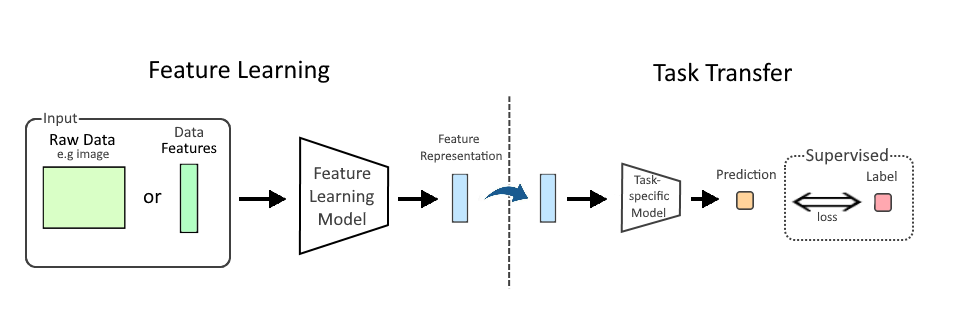
Artificial intelligence is often described in terms of models: large language models, vision systems, recommendation engines, robotics controllers. But in most real deployments, the model is only the visible layer. The real determinant of whether AI works in practice is the data pipeline underneath it.
A data pipeline is the system that moves data from its source to the place where it can be used by an AI model. That sounds simple, but in production it means a long chain of tasks: ingesting raw data, validating it, cleaning it, transforming it, storing it, and delivering it to training or inference systems in the right format and at the right time. When that chain is weak, AI systems become brittle, expensive, or outright wrong.
For industry readers, the key point is this: data pipelines are not just plumbing. They are the operational layer that turns messy real-world information into something a machine can learn from or act on. In AI, that layer is strategic infrastructure.
What a data pipeline actually does
At its core, a data pipeline performs a simple function: it transports data from one stage to another. In an AI context, that usually means moving data from business systems, sensors, logs, databases, or public sources into the environments used for training, evaluation, or inference.
The pipeline usually has several stages. First comes ingestion, where data is collected from source systems such as transactions, cameras, industrial sensors, web traffic, or user interactions. Next is validation, which checks whether the data is complete, structured correctly, and within expected bounds. Then comes transformation, where data is cleaned and reshaped so the model can use it. This might include removing duplicates, normalizing values, aligning timestamps, converting text into tokens, or turning images into standardized formats.
After that, the data is stored and served. For training, it may land in a data lake, warehouse, or feature store. For real-time AI applications, the same pipeline may feed an inference service directly with low latency. In modern systems, the pipeline is often split between batch processing and streaming, because some AI workloads can tolerate delay while others cannot.
Why AI systems depend on the pipeline, not just the model
It is tempting to think of model quality as mainly a matter of architecture, scale, or compute. Those matter, but data pipeline quality often determines whether the model ever sees the right inputs in the first place.
Training data that is incomplete, stale, or inconsistently labeled will produce weaker models, even if the underlying architecture is state-of-the-art. A fraud detection model trained on delayed transaction data may miss emerging attack patterns. A robotics system trained on poorly synchronized sensor streams may misread the world. A recommender system fed inconsistent event logs may optimize for artifacts rather than user behavior.
In other words, the pipeline shapes the model’s worldview. If the pipeline introduces bias, gaps, or latency, the model inherits those flaws. This is why many AI failures are not really “AI failures” at all. They are data failures that surface at the model layer.
Batch pipelines versus real-time pipelines
There are two broad categories of data pipelines in AI systems: batch and streaming. Batch pipelines process data in chunks on a schedule, such as hourly, daily, or weekly. They are common in training workflows, analytics, and offline feature generation because they are simpler to manage and easier to optimize for throughput.
Streaming pipelines process events as they arrive. They are essential for systems that need immediate responses, including recommendation engines, ad bidding platforms, factory monitoring systems, security detection, and many robotics and autonomous applications. Streaming architectures are more demanding because they must handle low-latency transport, fault tolerance, and continuous state updates.
In practice, many AI stacks use both. A company might train foundation models or domain-specific classifiers on batch data while serving live inference from a streaming pipeline that updates features in near real time. The engineering challenge is keeping those two views of the world consistent.
The hidden work: cleaning, labeling, and feature engineering
The most important tasks in a data pipeline are often the least glamorous. Raw data is rarely ready for machine learning. It may be missing fields, contain conflicting timestamps, use inconsistent units, or include noise from the collection process. Cleaning is the process of making that data usable without destroying the signal hidden inside it.
Labeling is another critical step, especially for supervised learning. Images need object tags, text needs sentiment or intent labels, and industrial events may need failure categories. Poor labeling is a common source of model drift and training error. At scale, labeling pipelines can become a full operational discipline, with quality checks, human review, and active learning loops designed to reduce cost while improving consistency.
Feature engineering is the stage where raw data is turned into model-ready inputs. In traditional machine learning, this might mean creating ratios, rolling averages, or time-windowed summaries. In modern AI systems, especially with deep learning, feature engineering may be less manual, but it has not disappeared. Even large models depend on preprocessing, tokenization, embedding generation, and feature stores that define how information is represented.
Why infrastructure teams care about data pipelines
For enterprises, data pipelines are increasingly an infrastructure problem, not just a data science problem. They affect compute utilization, storage costs, network traffic, and operational reliability.
A poorly designed pipeline can waste expensive GPU time by feeding training jobs incomplete or malformed datasets. It can create bottlenecks that delay retraining cycles and slow product updates. It can also make compliance harder, because organizations need to trace where data came from, how it changed, and who accessed it along the way.
This is why pipeline design now sits close to MLOps, data engineering, and cloud architecture. Teams need versioned datasets, reproducible transformations, lineage tracking, access controls, and monitoring for schema drift. In regulated sectors like healthcare, finance, and industrial automation, these are not optional features. They are table stakes for deployment.
What breaks when the pipeline breaks
When an AI system behaves badly, the failure often traces back to the pipeline. A model may look accurate in testing but degrade in production because input distributions have shifted. A sensor stream may arrive with missing packets. A database schema may change without warning. A data transformation step may silently drop rare but important cases.
These failures are dangerous because they can be subtle. The system does not always crash. Sometimes it just becomes less reliable. That is especially problematic in high-stakes environments such as autonomous machinery, industrial quality control, cybersecurity, or customer support automation, where small errors can scale quickly.
Good pipelines therefore include monitoring. They track data freshness, volume, schema changes, null rates, latency, and drift. In AI systems, monitoring the data is often more important than monitoring the model alone, because the model’s behavior is only as good as the inputs it receives.
The strategic takeaway for AI builders and buyers
If you are building or buying AI systems, the pipeline should be part of the evaluation from day one. Ask where the data comes from, how often it updates, how it is validated, how labels are maintained, and whether the same transformations are used in training and inference. Ask what happens when sources fail, formats change, or the business grows faster than the pipeline was designed to handle.
That matters because AI at scale is really a data logistics problem with compute attached. GPUs, models, and orchestration software get the headlines. But sustained performance comes from a pipeline that can keep feeding the system the right information, at the right quality, at the right speed.
The simplest definition is also the most useful: a data pipeline in AI is the machinery that makes machine learning possible in the real world. Without it, models are isolated demos. With it, they become systems that can be trained, updated, audited, and deployed reliably across an organization.
Image: AI Classroom at Universal Ai University.jpg | Own work | License: CC0 | Source: Wikimedia | https://commons.wikimedia.org/wiki/File:AI_Classroom_at_Universal_Ai_University.jpg