Why deep learning matters now
Deep learning is one of the main reasons modern AI systems can recognize faces, generate text, recommend videos, translate languages, and control robots. It is not magic, and it is not a single product. It is a method for teaching computers to find patterns in data by using layered neural networks. That simple idea has become a foundation for some of the most important systems in tech.
For beginners, the challenge is that deep learning is often described in either overly technical terms or inflated marketing language. The useful version is in between: deep learning is a pattern-learning approach that gets stronger as data, compute, and model size scale up. That is why it sits at the center of the AI boom and why GPUs, data centers, and energy infrastructure matter so much to its future.
The basic idea: a network that learns from examples
At its core, deep learning uses an artificial neural network, which is a set of connected layers of simple computation units. Each layer takes input, transforms it, and passes its result to the next layer. The “deep” in deep learning refers to having many layers, not just one or two.
You can think of it as a pipeline for progressively refining information. If the task is image recognition, the first layers might detect edges and textures. Middle layers might combine those into shapes or parts of objects. Later layers might identify that those shapes belong to a dog, a car, or a traffic light. The system is not explicitly programmed with those rules. It learns them from examples.
That is the key difference from traditional software. In classic programming, humans write the rules. In deep learning, humans provide data and a training process, and the model learns the rules on its own—at least statistically.
What a neural network is actually doing
Despite the metaphor, neural networks are not brains. They are mathematical systems built from weights, which are numeric values that determine how strongly one unit influences another. During training, the model adjusts these weights to reduce error.
Here is a simple example. Suppose you want a model to tell cats from dogs. You show it thousands of labeled images. The model makes guesses, compares them with the correct answers, and gets feedback on how wrong it was. Over time, it changes its internal weights so that the right answer becomes more likely.
This process is less like memorizing specific pictures and more like tuning a very large set of knobs until the system gets better at recognizing useful patterns. The result is a model that can often classify new images it has never seen before.
Training versus inference: the two phases beginners should know
Deep learning has two essential phases: training and inference.
Training is when the model learns from data. This is the expensive part. It requires lots of examples, heavy computation, and a process that can run for hours, days, or even weeks on clusters of GPUs or specialized accelerators.
Inference is when the trained model is used to make predictions. If you ask a chatbot a question, run a photo through a face recognition system, or use a recommendation engine on a streaming platform, that is inference. It is usually cheaper and faster than training, though large models can still require serious compute to serve at scale.
This split matters because it explains why deep learning is not just a software story. Training drives demand for high-performance chips, memory bandwidth, networking, and power delivery. Inference drives deployment decisions across smartphones, cloud platforms, enterprise data centers, and edge devices.
Backpropagation: the learning mechanism under the hood
One of the most important ideas in deep learning is backpropagation, the method used to update a network’s weights. In plain English, it is a way of figuring out which parts of the model contributed to an error and how much each part should change.
After the model makes a prediction, it measures the difference between its output and the correct answer. That difference is called the loss. Backpropagation sends that error signal backward through the network, layer by layer, so the system can adjust the weights in a direction that should reduce future mistakes.
You do not need to do the calculus by hand to understand the concept. The practical takeaway is that learning happens through repeated correction. The model is not given intelligence in a box; it is optimized through many tiny updates.
Why deep learning took off in the 2010s
Deep learning was not invented yesterday. The underlying ideas have existed for decades. What changed was the combination of three forces: more data, better algorithms, and much more compute.
First, digital systems produced enormous amounts of labeled and unlabeled data from images, text, clicks, sensors, and audio. Second, researchers improved training techniques so large networks could be trained more reliably. Third, GPUs made it practical to perform the massive matrix operations that deep learning depends on.
This compute angle is not incidental. Deep learning is unusually friendly to parallel processing, which is why GPUs became so central. The same architectural traits that make a GPU effective for graphics—high throughput, parallel arithmetic, fast memory access—also make it excellent for training neural networks. That is a major reason companies are racing to secure chips, build data centers, and expand power capacity.
Concrete examples of deep learning in daily life
Deep learning often hides inside products people use every day:
- Photo apps: Automatically tag faces, remove blur, or improve low-light images.
- Streaming and shopping recommendations: Predict what you might want next based on prior behavior.
- Voice assistants: Convert speech to text and interpret spoken commands.
- Translation tools: Learn language patterns well enough to generate fluent translations.
- Industrial inspection: Detect defects in manufacturing lines using camera feeds.
- Autonomy and robotics: Help systems recognize objects, estimate motion, or classify environments.
What these applications have in common is pattern recognition at scale. Deep learning is useful when the problem is too complex to hand-code but rich enough that examples exist.
Where deep learning works best—and where it doesn’t
Deep learning is powerful, but it is not the right tool for every task. It tends to work best when there is a lot of data, patterns are complex, and the cost of mistakes is manageable or can be constrained by testing and human oversight.
It struggles when data is scarce, when interpretability matters more than raw accuracy, or when the environment changes too quickly. Models can also inherit bias from training data, make confident errors, and behave unpredictably outside the conditions they were trained on. A system that looks impressive in a demo can still fail in production if the data distribution shifts.
This is why serious deployments emphasize validation, monitoring, and fallback systems. The best teams do not assume a model will be right; they design for the possibility that it will be wrong.
The practical takeaway for beginners
If you remember only a few things, make them these: deep learning is a way of learning patterns from data using multi-layer neural networks; training is the expensive learning phase, while inference is the use phase; and the whole system depends on data, compute, and careful engineering just as much as on algorithms.
For beginners, that framing is more useful than memorizing jargon. Deep learning is not merely “AI.” It is a specific class of methods that has become central because it scales. That scalability is why it now touches semiconductors, cloud infrastructure, consumer products, robotics, and enterprise software all at once.
Understanding deep learning at this level gives you a better read on the technology industry itself. When a company announces a new model, a new chip, or a new data center, those are often pieces of the same system. Deep learning is the software logic; chips and infrastructure are the physical machinery that makes it run.
For anyone trying to make sense of modern AI, that is the real starting point.
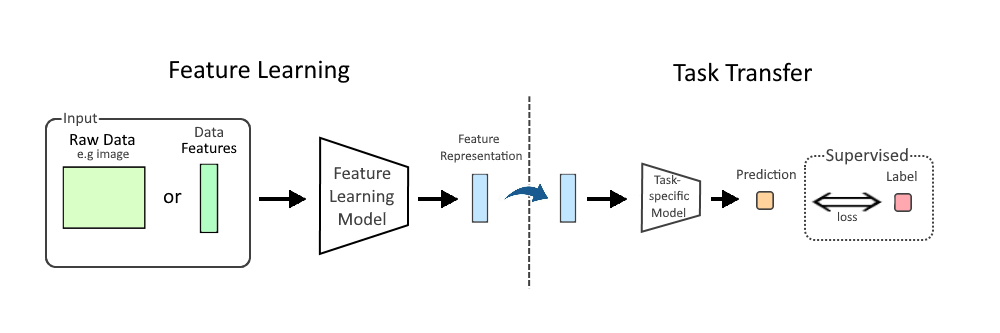
Image: Feature Learning Diagram.png | Own work | License: CC BY-SA 4.0 | Source: Wikimedia | https://commons.wikimedia.org/wiki/File:Feature_Learning_Diagram.png