The simplest useful definition
A neural network is a computer system built to spot patterns. It takes in data, processes it through a series of connected layers, and produces an output: a label, a prediction, a generated word, a control signal, or some other decision. The name comes from a loose resemblance to the brain, but that analogy only goes so far. A neural network does not think, remember, or understand in the human sense. It performs mathematical transformations that become useful because they can be trained on enough examples.
That distinction matters. When people talk about modern AI—image recognition, speech transcription, recommendation engines, chatbots, autonomous robots, and large language models—they are usually talking about neural networks of one kind or another. The systems differ in architecture and scale, but the core idea is the same: learn relationships from data instead of relying entirely on hand-written rules.
What a neural network actually does
Think of a neural network as a very flexible function. You give it an input, and it maps that input to an output. If the system is trained well, that mapping becomes good enough to identify a cat in a photo, predict the next word in a sentence, or estimate when a server rack will need more cooling capacity.
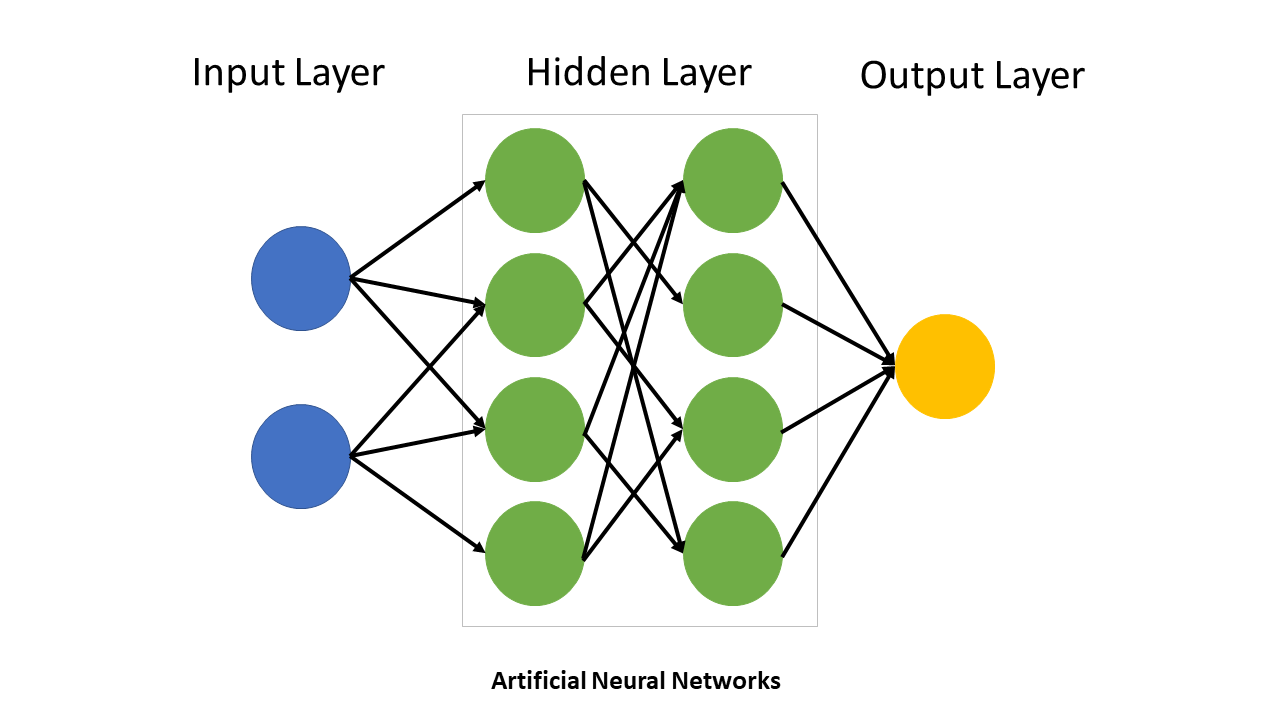
At its most basic, the network is made of artificial “neurons.” Each neuron receives numbers, multiplies them by weights, adds them up, and passes the result through a simple mathematical rule called an activation function. One neuron is not interesting. Thousands or millions of them arranged in layers become powerful because each layer can gradually turn raw data into more useful representations.
A useful mental model is this: the first layer notices very simple features, the next layer combines those into more abstract patterns, and later layers make the final decision. In an image model, early layers may react to edges or textures. Deeper layers may recognize wheels, faces, or signage. In a language model, early layers encode local word relationships, while later layers can represent syntax, context, and longer-range meaning.
The parts that matter: weights, layers, and activations
Weights are the tunable numbers inside the model. They determine how strongly one input influences the next step. During training, the network adjusts these weights again and again until its predictions improve.
Layers are the stages of computation. A network with only a few layers may solve simple tasks; a deep network can build complex abstractions from simpler ones. This is where the term “deep learning” comes from: neural networks with many layers.
Activation functions give the model its nonlinearity. Without them, the network would collapse into something too simple to capture real-world patterns. In plain English, activations let the model behave differently in different situations instead of making the same linear guess every time.
Those three pieces—weights, layers, activations—are the structural core. The rest is scale, data, and training discipline.
How training works, in practical terms
Training is the process of showing the model many examples and adjusting its internal weights so its outputs get closer to the right answers. If you are training a model to identify defective chips on an inspection line, you might feed it thousands of labeled images: good dies, cracked dies, contamination, misalignment, and so on. Each time the model makes a mistake, the training process nudges the weights to reduce that error next time.
The key mechanism is usually backpropagation, paired with an optimization method such as gradient descent. Backpropagation calculates how much each weight contributed to the error. Gradient descent then changes the weights in the direction that lowers the error. Repeated many times, this is how the network learns.
Training is computationally expensive. That is one reason GPUs, high-bandwidth memory, and data-center networking matter so much to AI. Neural networks are not just software; they are workloads. They can demand enormous matrix operations, large batches of data, and fast movement of parameters and activations across hardware. At scale, training infrastructure becomes a strategic asset, which is why companies such as Nvidia, AMD, and cloud providers compete so aggressively for AI compute.
A concrete example: spam filtering
Before generative AI became the dominant public story, neural networks were already doing practical work. Spam filtering is a classic example. A model can learn from past emails that messages containing certain patterns—suspicious phrasing, repeated domains, mismatched links, or abnormal sender behavior—are more likely to be unwanted.
The model does not need explicit human-written rules for every scam pattern. Instead, it learns statistical regularities from examples. That makes it more adaptable than a static rule engine, especially when attackers keep changing tactics. But it also means the model’s performance depends heavily on the quality of its training data and how closely future messages resemble the training set.
This same logic extends to fraud detection, medical imaging, predictive maintenance, warehouse robotics, and recommendation systems. Neural networks are useful when the problem is complex, the pattern is hard to encode manually, and there is enough data to learn from.
Why neural networks became so important
Neural networks are not new. What changed was the combination of larger datasets, better algorithms, and far more compute. As storage became cheaper, sensors proliferated, and internet-scale platforms accumulated data, models had much more to learn from. Meanwhile, GPUs made the matrix math efficient enough to train larger networks in a practical timeframe.
That shift helped neural networks outperform older machine-learning methods in fields like computer vision, speech recognition, and natural language processing. Once the performance gap became clear, the industry reorganized around them. The result is visible everywhere: in smartphone cameras that improve photos automatically, in industrial systems that detect faults, and in generative models that can draft text, code, images, and audio.
It is also why semiconductors and data centers have become part of the AI story. A neural network may be a software model, but its capabilities depend on the physical supply chain underneath it: accelerators, HBM memory, server interconnects, cooling, and power delivery. The model is the visible layer; the infrastructure is the constraint.
Where neural networks are strong—and where they fail
Neural networks are exceptionally good at pattern recognition, approximation, and tasks where the world is messy rather than rule-based. They can detect anomalies in industrial telemetry, classify medical scans, estimate demand, and summarize large text corpora. They often outperform older approaches when the input is high-dimensional and the underlying relationships are too complicated to model by hand.
But they are not magic. They can be brittle, opaque, and data-hungry. If the training data is biased, incomplete, or poorly labeled, the model can inherit those flaws. If the real-world environment changes, performance can drop. In safety-critical settings such as robotics, automotive systems, or medical workflows, that brittleness is a serious engineering issue, not a philosophical one.
Another constraint is explainability. A neural network may produce a correct answer without offering a human-readable reason. That makes deployment easier in some cases and harder in others. Industries with regulatory or safety requirements often need extra testing, monitoring, and guardrails before trusting model outputs.
Neural networks vs. rule-based software
Traditional software is written as instructions: if X happens, do Y. Neural networks are trained, not explicitly programmed in that way. This changes how developers work. Instead of describing every rule, engineers define the model architecture, prepare data, choose a training process, and evaluate performance.
That difference explains both the strength and the frustration of neural networks. They can handle complexity that would be impractical to code manually. But they are also harder to inspect and debug. When a rule-based system fails, the logic is usually traceable. When a neural network fails, the cause may lie in data quality, architecture choices, training settings, or distribution shift in production.
In practice, many systems combine both approaches. A factory robot may use neural networks for perception—recognizing objects, estimating pose, reading labels—but rely on conventional control software for deterministic motion planning and safety constraints. The same hybrid logic appears in finance, logistics, and enterprise software.
Why the term matters for the current AI era
When people say “AI,” they often mean a neural network that has been trained on a lot of data and deployed at scale. That could be a recommender ranking products, a vision model identifying defects, or a large language model generating prose. The public discussion can make these systems sound generalized and humanlike, but the engineering reality is narrower and more useful: they are specialized pattern engines with impressive flexibility.
For readers trying to understand the economics of AI, that framing is important. Neural networks create demand for compute, memory, power, and networking. They shape chip roadmaps and cloud capital expenditure. They also create new bottlenecks, from data quality to latency to energy use. In other words, neural networks are not just a software trend; they are a systems-level force affecting hardware design, data-center buildouts, and operational strategy.
What to remember
If you strip away the jargon, a neural network is a layered mathematical model that learns from examples. It takes inputs, adjusts internal weights during training, and uses those learned patterns to make predictions later. It is powerful because it can discover structure in data that would be difficult to specify by hand.
That power comes with trade-offs: heavy compute requirements, dependence on data quality, limited interpretability, and occasional brittleness when conditions change. Understanding those limits is just as important as understanding the promise. In modern AI, the most useful question is rarely whether a neural network is “smart.” It is whether the model is trained on the right data, running on the right infrastructure, and constrained enough to be trusted in the real world.
Sources and further reading
- Deep Learning, by Ian Goodfellow, Yoshua Bengio, and Aaron Courville
- Stanford CS229: Machine Learning lecture materials
- MIT Press: Artificial Neural Networks and Deep Learning resources
- NVIDIA Developer documentation on GPU-accelerated deep learning
- Google Research and OpenAI technical overviews of neural network-based models
Image: Neural network explain.png | Own work | License: CC BY-SA 4.0 | Source: Wikimedia | https://commons.wikimedia.org/wiki/File:Neural_network_explain.png


