Traditional software and machine learning both run on the same machines, but they behave like two different species of computation. Conventional software executes explicit instructions written by engineers. Machine learning systems infer patterns from data and turn those patterns into a model that makes predictions or decisions. That distinction sounds subtle at first. In practice, it changes how products are built, tested, deployed, monitored, and improved.
For anyone working in modern technology, especially in AI, infrastructure, or semiconductor-heavy environments, this is more than a theoretical difference. It affects the kind of compute you buy, the data pipelines you maintain, the debugging methods you trust, and the risks you inherit. A system that learns is not just a faster version of a system that codes rules. It is a different operating model entirely.
Traditional software starts with rules
Classic software is deterministic. If you give it the same input and the same code, it should produce the same output every time. A calculator, a payroll system, a routing engine, or a database query follows logic written by a developer. If the behavior is wrong, the problem usually lives in the code, the configuration, or the inputs.
That makes traditional software relatively legible. Engineers can inspect the code path, trace the bug, and patch the rule. The software does exactly what it is told, even when what it is told is wrong. In other words, it is brittle in a useful way: predictable, but only within the limits of the rules humans define.
This is why traditional software shines in tasks with clear logic and stable requirements. Tax calculations, access control, inventory updates, and transaction processing all benefit from explicit rules. The system is transparent enough to audit and reliable enough to enforce.
Machine learning starts with examples
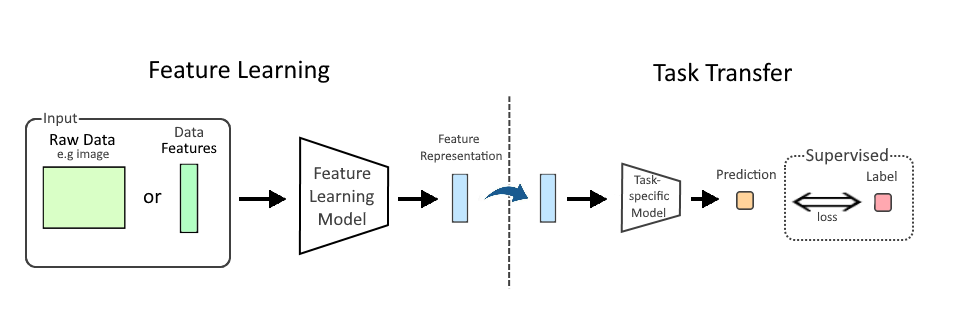
Machine learning flips the process. Instead of hand-coding the rule, engineers feed the system examples and let it discover statistical patterns. The result is a trained model, not a program in the traditional sense. The model contains weights, parameters, or decision boundaries learned from data.
For example, if you want software to recognize spam, you do not usually write thousands of if-then statements describing every suspicious email pattern. You show a model many emails labeled as spam or not spam, and it learns the signals that tend to separate one from the other. That can include obvious cues like sender reputation or more subtle interactions across word choice, links, timing, and metadata.
This ability to learn from examples makes machine learning powerful in messy, high-variance domains where rules are hard to maintain. Speech recognition, image classification, recommendation systems, fraud detection, and demand forecasting all benefit from pattern detection at scale.
The real difference is not output—it is where the logic lives
The easiest way to understand the divide is this: in traditional software, the logic lives in the code. In machine learning, much of the logic lives in the data and the trained model.
That changes the engineering workflow. A traditional application is improved by changing the source code. A machine learning system is improved by changing the training data, the model architecture, the feature set, the loss function, or the retraining process. Code still matters enormously, but it is no longer the only place where product behavior is shaped.
This is also why machine learning is often harder to reason about. The model may perform well on benchmark data, yet behave unexpectedly on edge cases. It may capture real patterns, but also inherit bias, noise, or hidden correlations from the training set. The software is not simply executing your intent; it is generalizing from examples, sometimes in ways that surprise even its builders.
Testing changes from correctness to performance
In traditional software, testing is usually about correctness: does the program do the right thing according to a specification? In machine learning, testing is more often about performance under uncertainty: how well does the model perform across realistic data, and how does that performance degrade when conditions change?
That shift matters. A software function can be tested against a fixed expected answer. A model that predicts whether a part will fail in a factory or whether a user will churn does not have a perfect answer in the same sense. You evaluate it probabilistically using metrics such as accuracy, precision, recall, F1 score, latency, calibration, or error rates on validation data.
And even a good metric can mislead if the real world shifts. A recommendation model trained on one user behavior pattern may perform poorly after a product redesign. A visual inspection model trained on one camera setup may degrade when lighting changes. In machine learning, success is often temporary unless the data pipeline, retraining cycle, and monitoring stack keep pace with reality.
Debugging moves from line-by-line to system-wide
Debugging traditional software usually means finding the faulty branch, function, or dependency. Machine learning debugging is more like diagnosing a complex system with multiple moving parts. A model can fail because the training set is skewed, the labels are noisy, the features are incomplete, the loss function is misaligned, or the deployment environment no longer resembles the training environment.
That makes observability more important, not less. Teams need to watch for input drift, output drift, latency spikes, confidence collapse, and silent degradation. They may also need to inspect subgroup performance, since a model can look strong on aggregate while failing badly for specific populations or edge cases.
This is one reason machine learning operations, or MLOps, emerged as a discipline. The work is not finished when the model trains successfully. It is finished when the model can be deployed reliably, monitored continuously, retrained safely, and rolled back when it starts to drift.
Compute is not the same either
Machine learning also changes the hardware conversation. Traditional software can often run efficiently on general-purpose CPUs. Some workloads need GPUs or accelerators, but many core applications do not require massive parallel compute.
Training machine learning models, by contrast, is compute-intensive and often data-center intensive. Large models may need clusters of GPUs, high-bandwidth memory, fast interconnects, and carefully managed storage systems. Even inference—the act of using a trained model—can become expensive at scale if millions of requests need low latency and high throughput.
That means ML is not just a software story. It is a systems story. Data movement, memory bandwidth, power delivery, cooling, and cluster orchestration all matter. In environments where AI workloads are becoming central, the difference between traditional software and machine learning shows up directly in infrastructure planning and capital spending.
What traditional software still does better
Machine learning is not a replacement for conventional software. In many cases, traditional code remains the better tool. If you need deterministic behavior, clear compliance rules, reproducibility, or exact arithmetic, explicit software is usually preferable.
ML can also be overused. Not every problem needs a model. If a rule can be stated clearly and is unlikely to change, encoding it directly is often cheaper, easier to test, and simpler to maintain. A machine learning system introduces training cost, data maintenance, uncertainty, and ongoing operational overhead.
That tradeoff is central to modern product design. The most effective systems often combine both approaches: traditional software for the parts that need precision and accountability, machine learning for the parts that involve ambiguity, pattern recognition, or scale.
What changes for builders and buyers
For builders, machine learning shifts the unit of engineering from code alone to code plus data plus model plus infrastructure. That means more attention to dataset quality, labeling, retraining cadence, evaluation design, and runtime monitoring. The developer’s job expands from writing logic to shaping the conditions under which a model can learn safely and predictably.
For buyers and operators, the question is not whether machine learning is smarter. The question is whether the system improves outcomes enough to justify the added complexity. In some cases, it delivers capabilities that rule-based software cannot match. In others, it introduces too much operational burden for too little gain.
The practical takeaway is simple: machine learning differs from traditional software not because it is magical, but because it relocates intelligence from hand-written rules into learned patterns. That makes it more adaptive, more probabilistic, and often more powerful—but also harder to control. The tradeoff is now one of the defining design decisions in modern computing.
As AI spreads across products, factories, data centers, and digital infrastructure, understanding that tradeoff is no longer optional. It is the difference between building a system that merely runs and building one that can adapt to the world it sits in.
Image: 130 Seater Classroom at Universal Ai University.jpg | Own work | License: CC0 | Source: Wikimedia | https://commons.wikimedia.org/wiki/File:130_Seater_Classroom_at_Universal_Ai_University.jpg