For much of the last decade, “the cloud” was the default answer to almost every infrastructure question. Need more storage? Put it in the cloud. Need more compute? Scale in the cloud. Need a new product launch? Build it in the cloud and worry about the hardware later.
That model still dominates, but it no longer stands alone. As devices get smarter, networks get denser, and applications become more latency-sensitive, a second architecture has moved from the margins to the center of strategic planning: edge computing. The result is not a winner-take-all contest. It is a division of labor.
Cloud computing and edge computing are best understood as two points on the same infrastructure spectrum. Cloud concentrates compute and storage in large, often geographically distributed data centers. Edge moves computation closer to where data is created or consumed — in factories, retail stores, cell towers, vehicles, hospitals, smart cameras, and local servers near the user.
The difference sounds simple. In practice, it shapes capital spending, network design, silicon demand, regulatory exposure, and the economics of AI deployment.
Cloud computing: centralized scale with enormous reach
Cloud computing is the model most people know. Instead of running software on local machines or private servers, companies rent access to computing resources over the internet. Those resources live in hyperscale data centers operated by providers such as Amazon Web Services, Microsoft Azure, and Google Cloud, as well as in private clouds managed by enterprises themselves.
The cloud’s core advantage is scale. A hyperscale data center can pack in massive numbers of servers, storage arrays, and networking gear, then distribute those resources across customers on demand. That makes it efficient for workloads that need flexibility more than proximity.
Typical cloud-native workloads include enterprise software, databases, analytics pipelines, collaboration tools, batch processing, backup and recovery, and model training for AI. The cloud is especially strong when the workload can tolerate some network delay and benefits from elastic capacity. If traffic doubles overnight, the cloud can absorb it. If a business wants to avoid buying hardware up front, the cloud converts infrastructure into an operating expense.
But cloud computing is not “virtual” in the abstract sense people sometimes imagine. It runs on real physical infrastructure: racks of servers, GPU clusters, fiber optic backbones, cooling systems, power delivery equipment, and increasingly large energy footprints. The cloud’s economics depend on how well that infrastructure is utilized. The closer a provider gets to full utilization without overcommitting capacity, the better the business model.
Edge computing: putting compute where the data is
Edge computing is what happens when moving data to the cloud is too slow, too expensive, or too impractical. Instead of sending every signal back to a distant data center, the system processes information near the source.
That source might be a factory robot deciding whether a part is misaligned, a warehouse scanner verifying inventory in real time, a security camera detecting motion, or a vehicle interpreting sensor data. In these cases, milliseconds matter. A central cloud data center may be powerful, but if the round trip across the network is too long, the application loses precision or becomes unsafe.
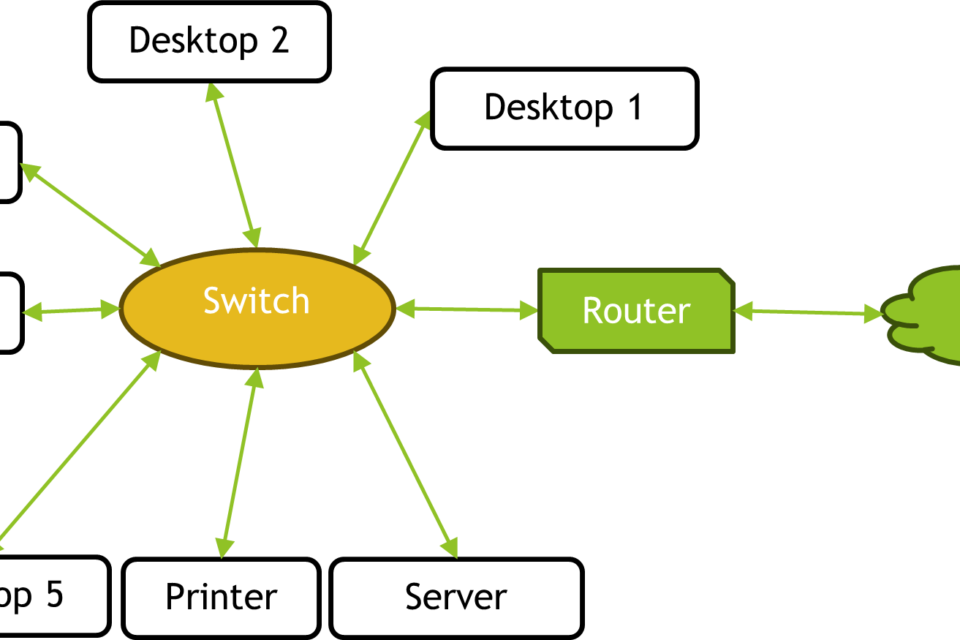
Edge is not a single place. It is a set of locations: devices themselves, on-premise servers, local micro data centers, 5G base stations, telecom edge nodes, and industrial gateways. What they share is architectural intent. They reduce dependence on a distant cloud by doing some or all of the work locally.
This matters for more than latency. Edge computing can reduce bandwidth costs by filtering or compressing data before sending it upstream. It can improve resilience when connectivity is patchy. It can help meet data sovereignty or privacy requirements by keeping sensitive information within a defined jurisdiction or facility. And in industrial settings, it can keep critical systems running even if the internet connection fails.
The real tradeoff: central efficiency versus local responsiveness
The cloud and edge are often presented as opposites, but the more accurate comparison is architectural tradeoff.
Cloud is optimized for central efficiency. By pooling resources, providers can achieve strong utilization, lower per-unit costs, easier management, and access to specialized accelerators such as GPUs and AI training clusters. It is ideal when the computation is heavy, the data is large, and a delay of tens or hundreds of milliseconds is acceptable.
Edge is optimized for local responsiveness. It reduces latency, limits data movement, and keeps systems operational closer to the point of action. It is ideal when decisions must happen immediately, when bandwidth is constrained, or when privacy and compliance rules favor local processing.
This is why the most realistic deployments are hybrid. A retail chain might use edge nodes in stores to process camera feeds in real time, while sending summarized data to the cloud for analytics. A factory might run machine control locally while using the cloud for long-term monitoring and maintenance forecasting. A hospital may keep certain imaging or patient systems on-premise while using cloud services for backup and collaboration.
In other words, the cloud often becomes the control plane and the edge becomes the execution layer.
Why AI is pushing edge computing forward
AI has accelerated the edge conversation because not all machine intelligence belongs in a remote data center. Training large models is still overwhelmingly a cloud and hyperscale activity. It requires dense clusters of GPUs, high-bandwidth interconnects, and major power infrastructure. That is a data center business, not an edge business.
Inference, however, is another story. Inference is the act of using a trained model to make predictions or decisions. Many inference workloads are increasingly being pushed toward the edge because they need to happen quickly, continuously, and sometimes privately.
For example, an AI-powered camera that detects safety violations in a warehouse cannot wait for the cloud to respond. A factory inspection system using computer vision benefits from local processing so it can stop a line immediately if it detects a defect. A voice assistant on a device may perform some functions locally to reduce latency and limit how often raw audio leaves the product.
This is one reason semiconductor design has become more strategically important. The edge market depends on efficient CPUs, GPUs, NPUs, accelerators, and networking chips that can run inference with lower power budgets than a full-scale server. Meanwhile, cloud providers continue to invest in custom silicon and massive GPU fleets to support training and large-scale inference at central sites.
The business case: cost, control, compliance, and reliability
When companies choose cloud, edge, or a hybrid of both, they are rarely making a purely technical decision. They are balancing four practical variables.
Cost: Cloud can reduce upfront capital spending, but ongoing usage charges, data egress fees, and GPU demand can add up quickly. Edge requires more upfront investment in local hardware, maintenance, and deployment complexity, but it can lower recurring transfer costs and reduce dependence on bandwidth-heavy workflows.
Control: Some workloads are easier to manage centrally. Others require local autonomy. If a system must keep functioning during a network outage, edge has the advantage.
Compliance: Data location matters. Regulations, contractual obligations, and internal governance rules may dictate where information can be stored or processed. Edge can keep data within a site or region; cloud platforms can also support regional controls, but not always with the same immediacy.
Reliability: Cloud services can be highly resilient, but they are still dependent on network connectivity. Edge can provide continuity when that connection degrades. The tradeoff is that distributed systems are harder to manage, patch, and secure across many endpoints.
What enterprises get wrong about edge
Edge computing is often marketed as if it automatically improves every workload. It does not. Moving compute outward increases operational complexity. Someone has to power the devices, monitor them, update software, secure them, and replace hardware as it ages. A thousand edge nodes can create a thousand small failure points.
That is why many edge deployments stall at pilot stage. The use case may be real, but the deployment model is harder than a centralized cloud rollout. Successful edge projects tend to have a narrow purpose: low-latency control, local analytics, or resilience in environments where connectivity is unreliable. They are not usually designed to replace the cloud wholesale.
Similarly, cloud is not always the best answer simply because it is familiar. If an application depends on instantaneous feedback, shuttling every input to a remote region can produce a worse user experience and a higher bill.
Where the market is headed
The next phase is not cloud versus edge. It is orchestration across both.
Enterprises are increasingly designing systems that decide dynamically where a workload should run. That means some data is processed on the device, some at a local edge node, and the rest in a central cloud. The architecture is becoming more layered, not less.
This shift has real implications for infrastructure vendors and policymakers alike. Data center operators are still building ever-larger campuses to meet cloud and AI demand. Telecom companies are positioning edge services near network endpoints. Hardware vendors are designing chips that can serve both centralized and distributed environments. And regulators are paying closer attention to energy use, data residency, and the concentration of digital infrastructure.
For businesses, the question is no longer whether to embrace the cloud. It is how much to centralize, how much to distribute, and which workloads demand immediate local action. That choice will shape not just IT spending, but product design, operational resilience, and competitive advantage.
The bottom line
Cloud computing gives organizations centralized scale, broad reach, and elastic capacity. Edge computing gives them proximity, lower latency, and greater local autonomy. The strongest systems use both — cloud for heavy lifting, coordination, and long-term storage; edge for fast decisions, resilience, and data reduction.
As AI, automation, and connected devices spread across industries, the line between cloud and edge will matter less as a branding distinction and more as a systems decision. The real challenge is not choosing a side. It is placing each workload where it can run fastest, cheapest, and most reliably.
Image: CC-IN2P3 data center (CNRS-20180120-0033).jpg | CC-IN2P3 data center | License: CC BY 4.0 | Source: Wikimedia | https://commons.wikimedia.org/wiki/File:CC-IN2P3_data_center_(CNRS-20180120-0033).jpg